Top 5 Pre-trained Word Embeddings
Introduction
Do you ever wonder how we can teach machines to comprehend text data? Humans have always been good at interpreting languages. Computers, on the other hand, may have a more difficult time doing this work than humans.

We know that machines are incredibly skilled at processing numerical data, but they become sputtering tools when we give them text input. Ergo, we must transform the text into something that machines can interpret, which leads us to the term ‘word embeddings.’ But first, let us acquire a few key pieces of information that will help us along the road.
What are word embeddings?
Word embeddings are numerical illustrations of a text. Sentences and texts include organized sequences of information, with the semantic arrangement of words communicating the text’s meaning. Extracting meaningful characteristics from a text body is fundamentally different from obtaining features from numbers. The goal is to develop a representation of words that capture their meanings, meaningful connections, and the many sorts of situations in which they are employed.
An embedding contains a dense vector of floating-point values. Embeddings allow us to utilize an efficient representation in which related words are encoded in the same manner. Based on the use of words, the distributed depiction is learned.
Pre-trained Word Embedding
Modern Natural Language Processing (NLP) uses word embeddings that have been previously trained on a large corpus of text and are hence called ‘Pre-trained Word Embeddings.’ Pre-trained word embeddings are a type of Transfer Learning. They are trained on large datasets that can enhance the performance of a Natural Language Processing (NLP) model because they capture both the connotative and syntactic meaning of a word. All of these word embeddings are useful during hackathons and in real-world scenarios.
TRANSFER LEARNING
As its name indicates, transfer learning is transferring the learnings from one job to the next. Knowledge from one model is utilized in another, increasing the model’s efficiency. As a result of this approach, NLP models are trained faster and perform more efficiently.

We require pre-trained word embeddings for a variety of reasons like analyzing survey responses, feedbacks, etc. Nevertheless, why can’t we just create our own embeddings from scratch instead of using pre-trained techniques?
The sparsity of training data and multiple trainable parameters make learning word embeddings from scratch is a tedious task. Using a pre-trained model also reduces the computing cost and makes training NLP models faster.
1. Lack of training data is a significant deterrent. Most real-world issues have a substantial number of uncommon terms in their corpus. As a result of learning these embeddings from the respective datasets, the word cannot be represented correctly. This could end in a waste of time. A vector that has been one-hot encoded is sparse (meaning, most records are zero). Imagine that you have a vocabulary of 10,000 words in your arsenal. Basically, you would create a vector whose 99.99% of the components are 0.
2. As embeddings are learned from scratch, the number of trainable parameters rises. A delayed training process develops as a result. A word’s representation can be confusing after learning embeddings from scratch.
Pre-trained word embeddings are the answer to all of the difficulties listed above. In the next part, we will look at several word embeddings that have been pre-trained.
1. Word2Vec
‘’Google’s Word2Vec is one of the most popular pre-trained word embeddings’’.

Tomas Mikolov created it at Google in 2013 to make neural network-based embedding training more efficient; ever since it seems to be everyone’s favorite pre-trained word embedding. The Google News dataset was used to train Word2Vec (about 100 billion words!).
[Take a peek at the official paper to understand how Word2Vec found its way into the field of NLP: https://arxiv.org/pdf/1301.3781.pdf ]
Word2vec, as the name indicates, represents each word with a specific collection of integers known as a vector. The vectors are carefully calculated so that an essential mathematical function (the cosine similarity between the vectors) shows the semantic relation between the words represented by those vectors.

A classic example of this is: If you take the man-ness out of King and add the woman-ness, you get Queen, which captures the comparison between King and Queen.
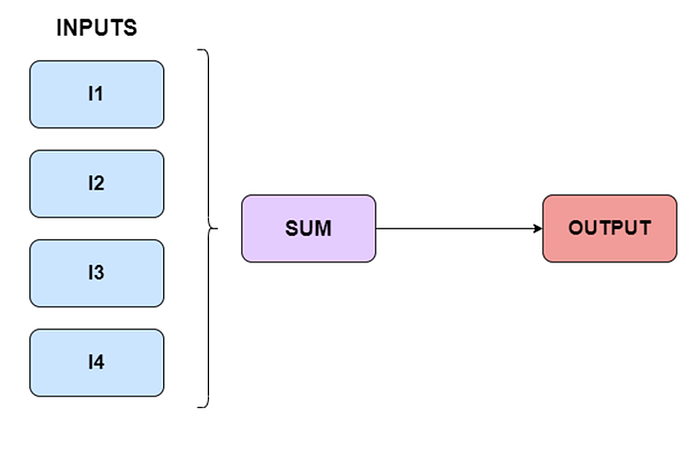
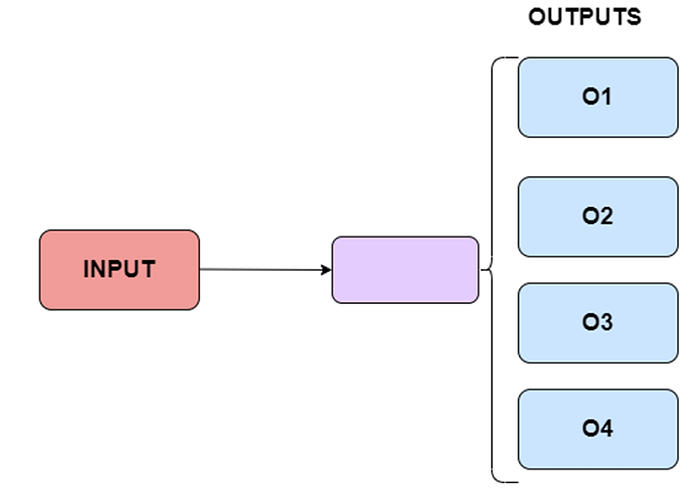
Continuous Bag-of-Words (CBOW model) and Skip-Gram Model are two distinct learning models used in word2vec word embeddings. In contrast, the Continuous Bag of Words (CBOW) model learns the target word from the adjacent words, whereas the Skip-gram model learns the adjacent words from the target word. As a result, Continuous Bag Of Words and Skip-gram are the exact opposites of one another.
Skip-Gram Model
A telling example of this is, take this simple phrase- ‘Dean poured himself a cup of coffee.’ We want to understand the embedding of the word ‘coffee.’ So here, the target word is ‘coffee.’ Now, let us see how the models mentioned above interpret this sentence:
Continuous Bag-of-Words
Input=[Dean,poured,himself,a,cup,of ]
Output = coffee
Skip-Gram Model
Input = coffee
Output=[Dean,poured,himself,a,cup,of]
Both models attempt to learn about words in their appropriate use context using a window of nearby words.

Using Word2vec, high-quality word embeddings can be read efficiently enabling more significant embeddings to be learned from considerably larger corpora of text. See, that was easy! Let us explore the next one now.
2. GloVe
GloVe is an unsupervised, count-based learning model that employs co-occurrence data (the frequency with which two words occur together) at a global level to build word vector representations. The ‘Global Vectors’ model is so termed because it captures statistics directly at a global level. Developed by Jeffrey Pennington, Richard Socher, and Christopher D. Manning, it has acquired popularity among NLP practitioners owing to its ease of use and effectiveness.
[If you’re searching for a thorough dig, here’s the official paper: https://nlp.stanford.edu/pubs/glove.pdf ]
In GloVe, words are mapped into a meaningful space where the distance between words is linked to their semantic similarity. It combines the properties of two model families, notably the global matrix factorization and the local context window techniques, as a log-bilinear regression model for unsupervised learning of word representations. Training is based on global word-word co-occurrence data from a corpus, and the resultant representations reveal fascinating linear substructures of the word vector space.
The question is: how can statistics convey meaning?
Examining the co-occurrence matrix is one of the most straightforward approaches to accomplishing this goal. How often do certain words appear together? That is what a co-occurrence matrix tells us! Co-occurrence matrices count the number of times a given pair of words appear together.
An illustration of how GloVe’s co-occurrence probability ratios operate is provided below.
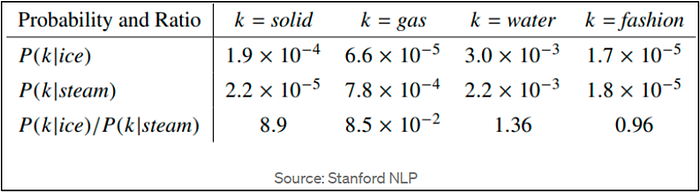
Where Pi is the ‘probability of ice’ and Pj is the ‘probability of steam’.
P(solid|ice) has a greater probability as ice is more comparable to solid than steam, as shown by P(solid|steam). A similar distinction may be made between ice and steam. P(fashion|ice) and P(fashion|steam) are independent probabilities, but they do not support the conclusion that there is no link between the two. So the concept behind GloVe is to represent words by considering co-occurrence probability as a ratio. P(fashion|ice) / P(fashion|steam) almost equals one (0.96).
“Raw probabilities cannot distinguish between important terms (solid and gas) and irrelevant words (water and fashion). The ratio of probabilities, on the other hand, can distinguish between the two relevant words more effectively.”
GloVe Embeddings are based on the principle that “the ratio of conditional probabilities conveys the word meanings.”
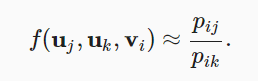
where,
● Ui,Uj → words in context
● Vi → words out of context
● Pik, Pjk → derived from the corpus
3. fastText
“As part of Facebook’s AI research, fastText is a vector representation approach”.

This quick and efficient technique lives up to its name. With a big twist, the concept is quite similar to that of Word2Vec. fastText builds word embeddings by utilizing words, but it goes one step beyond. It is composed of characters instead of words.
[Have a look at the official paper: https://arxiv.org/pdf/1607.04606.pdf ]
fastText breaks words down into n-grams instead of sending them directly into the neural network as individual words (sub-words). For example, The word “there” has the following character trigram:

In order to differentiate between the ngram of a word and the word itself, the boundary symbols < and > are added. For example, if the word ‘her’ is part of the vocabulary, it is represented as <her>. Thus, ngrams maintain the meaning of shorter words. Suffixes and prefixes can also be interpreted in this way.
There are two primary benefits of fastText. First, generalization is feasible as long as new words have the same characters as existing ones. Second, less training data is required since each piece of text may be analyzed for more information. fastText model is pre-trained for more languages than any other embedding technique.
4. ELMo
“A state-of-the-art pre-trained model, ElMo embedding, has been created by Allen NLP and is accessible on Tensorflow Hub”
NLP scientists across the world have started using ELMo (Embeddings from Language Models) for activities in both research and industry. This is done by learning ELMo embeddings from the internal state of a bidirectional LSTM. Various NLP tests have demonstrated that it outperforms other pre-trained word embeddings like Word2vec and GloVe. Thus, as a vector or embedding, ELMo uses a different approach to represent words.
[For further insight, you can check out the official paper here: https://arxiv.org/pdf/1802.05365.pdf ]
ELMo does not employ a dictionary of words and associated vectors but instead analyses words in their context. It expresses embeddings for a word by understanding the accurate phrase that contains that word, unlike Glove and Word2Vec. Due to the context-sensitive nature of ELMo embeddings, different embeddings can be generated for the same word in various phrases. For instance, consider these two sentences:

‘Watch’ is employed as a verb in the first sentence but as a noun in the second. Polysemous words are those words that appear in diverse contexts in different phrases. GloVe and fastText are unable to handle words of this kind. On the other hand, ELMo is equipped to handle polysemous words.
5. BERT
BERT (Bidirectional Encoder Representations from Transformers) is a machine-learning approach based on transformers for pre-training in natural language processing. Jacob Devlin and his Google colleagues built and released BERT in 2018. Showing state-of-the-art results in an array of NLP tasks has gained significance in the machine learning field.
[Interested in learning more? You may read the official documentation: https://arxiv.org/pdf/1810.04805.pdf ]
Technically, BERT’s breakthrough is the application of Transformer’s bidirectional training to language modeling. Using Masked LM (MLM), the researchers could train models in a bidirectional fashion that was previously unachievable. A text sequence was analyzed from left to right or from left to right, respectively, in earlier efforts. Using bidirectional training, the study shows that a model’s understanding of linguistic context and flow may be enhanced over single-direction models.
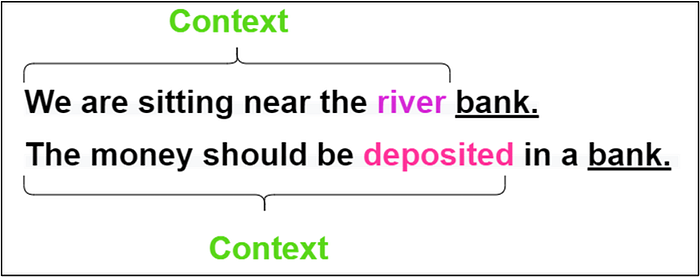
The left and right contexts must be considered before comprehending the meaning of the sentence. BERT does just that!
Half of BERT’s success comes from its pre-training stage. That is because the models become more sophisticated as they are trained on a massive corpus of text.
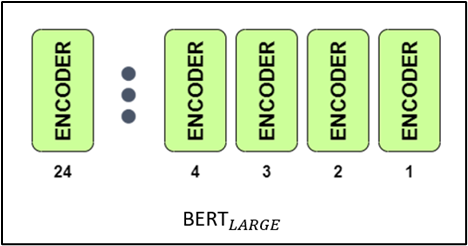
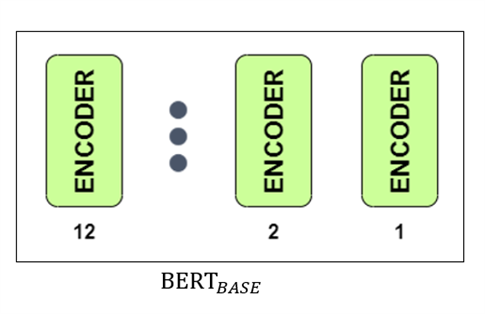
Originally, there are two different versions of the BERT in English:
- BERT BASE: 12 encoders with 12 bidirectional self-attention heads
- BERT LARGE: 24 encoders with 16 bidirectional self-attention
Thus now, NLP problems consist of only two steps:
1. An unlabeled, huge text corpus can be used to train a language model.
2. Use the vast knowledge base that this model has accumulated and fine-tune it to particular NLP tasks.
With an understanding of both left and the right context, BERT is used to pre-train deep bidirectional representations from unlabeled text to improve performance. Adding a single extra output layer to the previously trained BERT model allows it to be fine-tuned for a wide range of Natural Language Processing applications.
Conclusion
This is the final destination! Knowing these pre-trained word embeddings will certainly give you an edge in the field of NLP. In terms of text representation, pre-trained word embeddings tend to capture both the semantic and syntactic meaning of words.
I hope you liked and found this blog useful! Check out my page for more informative blogs. Feel free to reach out and connect with me on LinkedIn.
